
![]()
Genetic transmission is the mechanism that drives evolution. DNA encodes all the information necessary to make an organism. Every organism’s DNA is made of the same basic parts, arranged in different orders. DNA is divided into chromosomes, or groups of genes, which code for proteins. Asexually reproducing organisms reproduce using mitosis, while sexually reproducing organisms reproduce using meiosis. Both these mechanisms involve duplication of DNA, which then gets passed to offspring. RNA is a key component in the duplication of DNA.

Lecture by Dr. Stephen Stearns / 01.14.2009
Edward P. Bass Professor of Ecology and Evolutionary Biology
Yale University
Introduction
![]()
![]()
![]()
So I want to start by posing you a problem. Jill and John are going to have a baby, and Jill’s got blue eyes and John’s got brown eyes. Okay? All of the other men whom Jill knows have blue eyes. The baby has blue eyes. Should John be worried? John’s got brown eyes, the baby’s got blue eyes, should John be worried?
Well, we can assume that brown eyes are dominant to blue, which roughly speaking is correct. The actual situation is a bit more complex. In fact, if you want to write a paper on the evolution of eye color and the genetics of eye color, there’s a lot out there. But this is approximately correct. And John comes from an island where one percent of the people have blue eyes. So that, just on the face of it, would indicate that maybe John ought to be worried.
But in fact just exactly how worried should he be; just based on genetics, not based on behavior or rumors or anything like that? Well we’ll come back to that. I do that at the beginning just to point out that there are interesting issues here, and that they are things that touch our daily lives.
So now I’m going to run through, as much as I can, genetics, in the next forty minutes. And please speed me up or slow me down, as you wish, and don’t hesitate to interrupt. Some of this may already be very familiar to you. So the genetic material is deoxyribose nucleic acid. We have known that since 1945, and we’ve known its structure since 1953. And this is actually an extremely important point: Genes are solid particles that are transmitted from parent to offspring. They are not fluid. They’re actually material stuff.
Structure of DNA and Genetic Material
![]()
DNA Structure / Wikimedia Commons
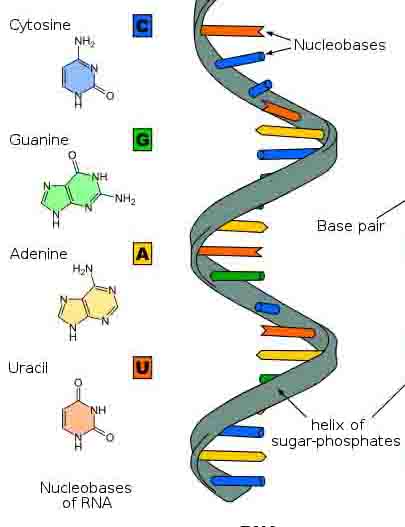
And we know exactly what it is. They encode information, as sequences of nucleotides, and in the DNA it’s adenine, thymine, guanine and cytosine. So you can think of those as four letters. They string into a linear chain to form a molecule, and these, uh, there are two strands that are twisted around each other to form a double helix. So it looks like that. The sugar phosphate strands form the backbone, and then the nucleotides are glued onto the backbone and they form pairs; so adenine pairs with thymine, and guanine pairs with cytosine.
The sugar phosphate backbone is the same in every DNA molecule on the planet, and the information in the molecule is in the sequence of nucleotides. You can think of that as letters forming words. So these are big molecules. If you were to put all the chromosomes in your nuclei together, and just for one cell, and string them together, one haploid copy is exactly one meter long. So when they say it is a macromolecule, it is a serious macromolecule. It is a big thing. So just chop this piece of measuring tape up into 26 pieces and you get about the size that you’ve got in each of your chromosomes. Okay?
When I first isolated DNA from sugarcane, and condensed it in ethanol, it came out, in the ethanol mixture, as a bunch of white, stringy strands, and I could wrap it around a glass rod. This is big stuff. So we’re not talking about tiny, weensy, little molecules. DNA is a biggie, and it’s very stable.
Now, how does this relate to organisms? Well that’s the issue of genotypes and phenotypes, and that’s a question of information and matter. So there’s a general principle here that’s quite intriguing and it has to do with how you turn information into matter. The genotype is basically the info in the DNA, and every cell in your body has got all the information in it that is needed to build a whole organism.
That, by the way, is an interesting statement, because if we can overcome some of the genetic programming of the oocyte, of the egg, we could, in principle, simply put a cotton swab into your cheek and take one cell off of your cheek and then do fancy reproductive medicine and clone you, off of just the DNA in a cheek cell. Now it turns out that the developmental machinery in the egg is really critical, and it’s hard to do that. But just from the point of view of the information, any cell in your body could be used to make another you. I can pull out a hair cell, take a cell off of the root of the hair, do the same thing.
The phenotype–basically you should think of that as you. Okay? That’s the material organism. It’s built according to genotypic instructions. So the genotype contains information, the phenotype contains matter, and the transformation from information into matter is done by developmental biology. Decoding that transformation is one of the major research agendas for the twenty-first century in biology. It’s called the construction of the genotype/phenotype map. That’s kind of modern jargon for developmental biology.
So where does the DNA actually sit in the cell? Well here’s some more vocabulary. I’m building vocabulary for those of you who haven’t been in biology recently. I’m going to say a few words here. The eukaryotes, the things that have a real nucleus–which includes us and all other multi-cellular organisms, plus a whole bunch of single-celled ones–they have cells that have a nucleus and the DNA in the nucleus is contained in chromosomes, and these chromosomes are a long structure that has kind of a central scaffold, it’s got a central mirror. That’s labeled 2 here, on the slide. And the DNA itself is actually wrapped around proteins in the chromosome.

Eukaryote / Wikimedia Commons
In the prokaryotes, which are the things that lived on this planet for about the first two billion years of life–that is, bacteria and archaea–they are single-celled organisms, and their DNA is basically not in separate chromosomes, but all in one circular loop. So it’s a circular chromosome; it’s attached to the cell wall. So there’s a big difference in the way that eukaryotes and prokaryotes are organized, and in fact the eukaryotic nucleus is very probably the evolutionary residue of a prokaryote; that’s where that organelle probably came from.
The number of chromosomes is usually constant, within a species, although there is some variation. You get 23 from your mom and 23 from your dad. So you’ve got 46 sitting in every cell of your body, except your red blood cells which don’t have a nucleus. That dual set, one from mom and one from dad, together it’s called the diploid condition. Okay? So d-i–2; from Greek, diploid.
And in contrast to that, your eggs and your sperm are haploid. So the gametes are haploid. They have one set. Haploid means one set of chromosomes. So the haploid number in humans is 23. The diploid number is 46. World record for a eukaryotic minimum chromosome number is 1. Ascaris, a nematode that lives in the gut of dogs, has 1 chromosome. World record for maximum number of chromosomes? Actually it’s probably also in ascaris, but in the somatic condition. That one chromosome falls into about 1000 pieces when it develops. So chromosome number varies widely.
They’ve got genes and other things in them. You can think of a chromosome as being about 1000 genes, and you can think of a gene as having several thousand nucleotides in it. And you can think of a gene as being a segment of DNA that tells a cell to make a particular protein, a particular structural RNA, and through splicing and other things there are various other classes of RNA that are now important; regulatory RNAs.
You’re made out of proteins and materials whose construction is basically governed by the actions of proteins. And so the DNA in your genome is a set of instructions on how to make what kinds of proteins at certain places and times to control the construction of the organism and determine the uniqueness of the species. This, uh, you know, in a few words, describes something which is incredibly complicated and beautiful.
And if you think about how complicated your eyes or your brains or your livers or whatever else is, and you think about that for all of the ten to a hundred million species of organisms on earth, the amount of information stored in the genomes of the organisms on earth is just absolutely astounding. And by the way, when one goes extinct, it’s kind of like burning the library at Alexandria, and we lose all of that information.
Okay, genes are in specific locations and they come in different forms. So again, this is vocabulary building. We call the place that a gene is found on a chromosome its locus; this is in classical genetics. And genes can be found in different versions. We call those different versions alleles. So, for example, the gene for eye color is either blue or brown. Those would be the allele for blue or the allele for brown.
If you are carrying two different versions of the gene–you got one from your mom and you got one from your dad and they’re different–then you’re a heterozygote, and we call that condition the heterozygous condition. If you got the same one from both parents, then you’re a homozygote, and we call that the homozygous condition.
What does a gene look like? Well there’s a lot now that’s known about this, and as a matter of fact I encourage you to do things like go on the Web and just type gene structure, and have a look at all the diagrams that pop up. Normally a gene has got a codon–that is, three nucleic acids–that say, “This is where you’re going to start reading me off.”
And then it’s got another one down at the end that’s a stop codon, that says “That’s where you stop.” And then in between that you’ve got a long string of DNA–this is in eukaryotes, not in prokaryotes–a long string of DNA, and some of it is going to end up coding for protein and some of it is not. So the part that will code for protein we call the exons; the part that is going to be cut out and spliced and put into messenger RNA, to go out and make protein. And the part that is not we call introns. So not all the DNA is going to go out and become protein.
DNA Replication and Its Implications
RNA / Wikimedia Commons
The central dogma of molecular biology, basically, is that DNA makes RNA makes protein. And transcription is copying the DNA into messenger RNA, and that’s done with complementary pairing, and in the process, the thymine is replaced by uracil in the messenger RNA. The introns are cut out and discarded. The exons are spliced together and the RNA is then translated into protein in the ribosome.
There’s a lot of activity here for RNA. RNA is doing a lot of stuff, and in fact it’s because of the amount of engagement of RNA in this very, very basic process of life that we think that RNA was probably the original genetic molecule, and that DNA evolved after RNA, and then all of this process developed after that. The reason for that is that RNA has a very high mutation rate; DNA has a low mutation rate. But RNA can be an enzyme and DNA is not. So RNA was a–both an information storage molecule and an enzyme, at the beginning, close to the beginning, of life, and then DNA came along later.
So this is a picture of the structure of genes and the process that goes on when the DNA is transcribed into RNA. The RNA is spliced and assembled into a molecule that is then going to code for a polypeptide; or a big polypeptide is a protein. And that will then go through a ribosome to make protein. So the messenger RNA–and by the way, heh, when I was sitting in this room in 1965, I was taught about messenger RNA and the faculty would laugh and they would say, “Nobody’s ever seen one.”
That was forty years ago. Now they are the basis of high-tech genechips, and people work with them all the time. But that’s–you know–this kind of ghost in the machine, from forty years ago, became very concrete by about twenty-five years ago.
Transfer RNA is a much smaller molecule. Transfer RNA, if you think of messenger RNA as being that big, transfer RNA is about that big. And it is the molecule that matches the genetic code, that’s sitting there in the messenger RNA, to a particular amino acid. So you can think of–say if this is the messenger RNA sitting here, the transfer RNA is coming along and sitting down on the messenger RNA and matching the code on it, and then on its other end it’s carrying–like right here, where I’m wiggling my finger–it’s carrying an amino acid. And this whole process will get fed through a ribosome, and out at this end of it the amino acids will get joined together. So the RNA will go out one part of the ribosome, and out of another part will come the growing chain of the protein.
So the transfer RNA is actually the translation device–it is what implements the genetic code–which comes in units called codons. So it takes three nucleotides to specify one amino acid. And you can think of it like this. The DNA is a codon sequence. It gets translated into an RNA, and then in units of three–okay, so in chunks of three nucleotides, the RNA gets translated into protein.
Just to repeat this message, RNA is playing a big role in this whole process, and there’s good reason to suspect that it was the original genetic macromolecule. There’s an interesting implication in this, and I will not shy away from telling stories like this during the course. Information is flowing out from the genotype into the phenotype. It doesn’t go in the other direction. That’s very important, that it doesn’t go in the other direction.

Photo of German biologist August Weismann / Wikimedia Commons
This is a re-statement of something that August Weismann said in the nineteenth century. He said that there is a distinction between the genotype–the germline, which is the genotype–and the soma, which we now call the phenotype. And Weismann basically said in the 1880s that information flows from the genes out into the organism and not back in the other direction.
Now the implication of that is that evolution of acquired characteristics won’t work. In other words, if during my lifespan I acquire a healthy tan, my child will not inherit it because the information on tanning isn’t going to go back into my genome and get transmitted to my kids. If I develop calluses on my feet, they will not be transmitted. If a giraffe stretches its neck on the savanna to try to get to the top of the tree, and thereby actually does physically lengthen its neck by a couple of centimeters, that will not get transmitted to the next generation. Okay?
So that would be evolution of acquired characteristics–characteristics acquired during the lifetime of the parent–and it doesn’t work; that’s not how evolution works. You’re probably sitting there wondering, well how does it work? Hey, that’s what this course is about; you’re going to find out, don’t worry.
Now there was a guy named Trofim Lysenko, who was a demagogue and a corrupt guy; a pretty evil man. He claimed that evolution by acquired characteristics would work, and it would work very rapidly. This would allow crop selection to go on in a period of one generation, rather than ten or a hundred generations, and that therefore in Russia Stalin would be able to move people into Siberia and into areas where crops were not currently grown; and Lysenko said, “And we can guarantee you, scientifically, that these crops will work.”
The science was wrong and millions of people died, because they starved to death. Communist China was influenced by Stalin, and in fact Mao bought this stuff for awhile and carried out some similar policies during the Great Leap Forward, in the 1950s, and millions of people starved to death in China as well. The Chinese found it a little bit easier to get rid of this incorrect, this bad science, because after all it was a Russian import. Right? So you could throw it out a bit more easily than the Russians could.
Lysenko, in fact, persisted for quite a while in Russia, and when he was denounced by geneticists who told–were trying to tell Stalin that it was bad science, Lysenko arranged to have them killed; and they were killed, they were executed. Vavilov died in the gulag in 1943; one of the greatest evolutionary geneticists of the twentieth century.

Photo of Russian botanist and geneticist Nikolai Vavilov, 1933 / Wikimedia Commons
So the point of this is that there’s some important stuff about genetics, and it’s not just abstract. It’s affected science policy, it’s affected international relationships, and it’s affected the ability of agricultural practices to support human populations. Ideas have very important consequences, and this is just one of the first that you’re going to run into, in this course.
Okay, back to genetics. Whoosh. When the cells divide, the DNA replicates and each daughter cell gets a complete copy. This is how inheritance works. Okay? This is why you look like your parents. During replication the ends of the DNA strand are loosened and opened up so that in the notch between the two strands the nucleotides can be inserted. And all of this is done with complex enzymatic machinery and it’s done extremely precisely.
Only one mistake in about a billion nucleotides occurs in DNA. It’s almost impossible for humans to construct a system that has that degree of reliability. Obviously this precision has been an extremely important thing. Natural selection has worked very hard to get those enzymes that precise. When a mistake does occur, that is one source of mutation. And, in fact, the more frequently DNA is copied, the higher the mutation rate. So that’s one place where mutations come from.
When this is going on, this copying is going on in the process of the development of, uh, a multi-cellular eukaryote, like yourselves, or when it’s going on in an asexual, uh, eukaryote, basically what happens is the chromosomes go through the process of mitosis. And in mitosis what–what’s going on is that the chromosomes will be duplicated, they will line up at a plate, at the center of the cell; spindles will form. So these are proteins, these react in the fibrils here, and they are anchored to an organizing center, which is at the poles of the cell, and they attach to the centromeres of the chromosomes, and they pull one copy into each cell, and then the cell splits.
So that’s physically how the copying occurs at the DNA level and then at the chromosomal level, in the cell. And the picture basically is a stained mitosis caught in an onion root tip cell; which is sort of the classical place to observe this.
The important result of this is that if you’ve got two genes, A and a, that are alleles at the same locus, the two versions of the gene at the same place on the chromosome, mitosis basically consists of a doubling–of first a doubling of the chromosome, so you have enough copies to end up with. They line up at the middle of the cell, and then the spindle apparatus pulls one copy of the A and one copy of the a–in this slide they’re on different chromosomes–into each of the daughter cells.
What about meiosis? Meiosis is the process that produces gametes. So it takes the diploid parent down into a haploid gamete. So it’s a reduction division. The process is more complicated, and in fact it is like sticking two mitoses together in a sequence, but with a bit of additional machinery.
So the first thing that happens is that the chromosomes are duplicated and they are then actually duplicated again. Then out of, uh, out of the original chromosome there are two–out of the original cell. You’re going to go through a process first of duplication, another duplication, and you’re going to reduce them each twice by going through two mitoses in, uh, in sequence. And as a result of that, each haploid gamete is getting one original chromosome, or the other, but not both.
That’s a cartoon of meiosis. Meiosis is actually much more complicated than that, and is much more precise than I’m able to indicate with these kinds of stick diagrams. But for today’s purposes the main thing to remember about it is that meiosis takes a diploid parent and from the diploid parent generates haploid gametes, and each haploid gamete is getting one original chromosome, or the other, but it doesn’t get both.
Mendel’s Laws

Photo of Gregor Johann Mendel, 1932 / Wikimedia Commons
There’s a great paper that was written back in 1907 by a geneticist on this issue: Does the behavior of chromosomes explain Mendel’s Laws? And it does. So Mendel’s First Law is that if you have two alleles, two members of a gene pair, when they segregate into the gametes, one goes into each gamete; that’s Mendel’s Law of Segregation. So half of the gametes from a heterozygous Aa, will carry the A allele, and half of them will have a little a allele.
So this is the law that allows us to predict what the genotype ratio should be in the offspring, and that allows us to notice any deviations from that genotype ratio. So I’m jumping ahead a little bit here to Punnett diagrams. Just make a note in your head that this fact of segregation is the basis for our being able to predict what the offspring will be like if we know what the parents are like; at least it’s part of it.
So if you have two heterozygotes who are mating with each other–so the male gametes have either A or a, and the female gametes have either A or a, it is Mendel’s Law of Segregation which tells us that we can expect those gametes to be equally likely. The probability is 50% in each case. When they then come together to make a zygote that’s going to grow up to be the offspring, then these–we just multiply these probabilities together. So .5 times .5 gives us .25, and each of these kinds of zygotes is equally likely; 25%.
However there was a reason that we wrote A and a. If A is dominant, that is say it’s brown eyes, and a is recessive, say it’s blue eyes–and remember our baby with issues–then the ratio here is 3:1. That’s only true because–it’s 3:1 because in these three cases we have a A, and in this one case we don’t. So the ratio is 3:1.
It was this observation of 3:1 ratios in the offspring of heterozygote crosses that caused Mendel to postulate the idea that hey, some genes are dominant and some genes are recessive. If a gene’s dominant, you can see that fact in the phenotype; you can see that the allele is present in the phenotype. If it’s recessive, you can’t see the presence of the gene in the heterozygote. Its presence is covered up by the dominant one.
Mendel’s Second Law: What happens when we’re looking at two genes and they’re on different chromosomes? Well Mendel’s Second Law basically says that the events that occur at the different chromosomes are independent of each other. So genes that are sitting on one chromosome are going to be assorting independently to genes that are sitting on other chromosomes.
So in this picture you can see that if we have Aa–and this would be a Aa heterozygote; this is a Bb heterozygote. They are depicted as already having been copied. Okay? So they’ve been duplicated so that they can start going through the process of meiosis. And what’s going to happen is that we’re going to pull them apart.
We’re going to make four gametes out of each of the chromosomes. This combination, where you get AB and ab, is just as likely as this combination, where you get Ab and aB. Okay? So that’s tracking what happens when you have genes on two different chromosomes that are forming gametes. That’s Mendel’s Second Law.
So meiosis is capable of producing genotypes that are different from the parental genotype. I’ll pause for a moment there–I’m not just going to keep running through this slide–because I want to tell you that this is the essence of sexual reproduction. The fact that the offspring gene–genotypes are different from the parental genotypes is the essential evolutionary fact about sex.
It can be achieved in a lot of different ways, but it means that sex produces offspring that are not copies of the parent; they are all different from the parent. And there are two genetic mechanisms that do it. I just showed you the first one. If you’ve got the genes on different chromosomes, they assort independently. If they’re on the same gene–chromosome, you can have crossing over. Okay? So crossing over means that chromosome parts are exchanged during meiosis, and it produces new combinations. Like this.
It’s easiest to show you just with a diagram, rather than with words. So when we’ve made the copies of the chromosomes and they are lined up–I think this is in Prophase 1, if I’ve got my phases right in meiosis–it is possible that there will be a break and then a rejoining at a certain spot, and this will be done where the DNA sequences are very similar. So the chromosomes can break and be rejoined, and the product of that is gametes that are different. These are recombinant gametes generated by crossing over.
These combinations, this kind of genetic variation, is something that’s going on in every generation. The estimate for the human genome is that actually in order to go through meiosis, there must be a crossing-over event, and it is thought that every human chromosome experiences one crossing-over event every generation, roughly; probably true for most organisms. So these things are continually being shuffled.
And the point of that is that there are two mechanisms of recombination. Remember this. Okay? When we say that the genes recombine, they do it both because the chromosomes get shuffled, and because there is crossing over. The crossing over generates new combinations within chromosomes and the chromosome assortment generates new combinations within the genome; both things are going on.
Mutations and Their Consequences

Now mutations are also going on in every generation, and they produce changes in DNA sequences. Some of them make genes that are functional. Some mutated genes have improved. Many don’t, many have worse function. A lot of them are neutral. And it’s mutations that occur in the germline–that is, in the cells that will form eggs and sperm–that get transmitted to offspring. They have evolutionary significance. So they change the information that’s transmitted over evolutionary time.
Mutations that occur in somatic cells are things that lead to cancer. Cancer is a mutational process, and every cancer is a little evolutionary process that occurs just within the lifetime of the person who has it.
Ultimately, if you go back, through the history of life, mutations are where all genetic variation came from. So it’s important to understand basically what’s going on here. We refer, on the one hand, to point mutations. That’s where you just change one nucleotide, and there’s a category–there are categories of point mutations. You can have substitutions, you can have deletions, and you can have–a deletion of an entire codon will not cause a change in the downstream amino acids.
So if you take out three nucleotides at once, there won’t be any change in the coding for the remaining amino acids. But if you take out one or two, you’re shifting the reading frame. So if you have a deletion of one nucleotide or two nucleotides, it changes everything downstream, from that point. So one or two deletions can have really big effects on the information content of the whole genome. We call those frameshift mutations.
Mutations also occur at higher levels. You can have chromosomal mutations where you delete entire genes. So if I say we delete B, I want you to think now that we’re taking out maybe 3000 nucleotides. The whole gene disappears; everything from the start codon to the stop codon. We can duplicate a gene, so we get two copies, or we can invert them.
These are very important evolutionary processes. If you duplicate a gene, you can use the old copy to keep things working while you innovate with a new copy. So gene duplications are really important. Your genome has been completely duplicated twice. We can see that in the HOX genes; you’ll see that in a few lectures. But in the course of vertebra evolution, once back about with the hagfishes, in the Agnatha, and then once between the Agnatha and the higher fishes, the entire genome was duplicated, and it is thought that this duplication of information may very well have been associated with the fact that there was radiation and a generation of a lot of morphological complexities, because we had duplicated the entire library. You could keep one of them going, to keep everything running, and you could use the other one for innovation. So duplications are important.
Now, to get back to John, Jill, and the baby with issues. Remember I said that John came from an island where the population had a 1% gene frequency. Well we need to think about the whole population then.
Now I want you to think about an out-crossing, sexual diploid population that produces haploid gametes–it could be the population of Connecticut, it could be the population of New Haven, the population of Pitcairn Island–and focus on one gene that occurs as two alleles. Okay? We’ll call them A and a.
We’ve got Mendel’s Laws going on. So we have random fair assort–assortment of alleles into gametes, we have random fusion of gametes into zygotes, and we can put that into a Punnett diagram. So this would be for heterozygotes, Aa, mating with Aa. If we look at it as a population diagram, then the frequencies can be anything. It doesn’t have to be heterozygote frequencies. We can just say if there’s random mating of individuals in this population; some of them are homozygote, some of them are heterozygotes.
We have a population of eggs and a population of sperm, and the frequency of A we will call p, and the frequency of a we’ll call q. And it’s important to remember–and this is a place where people just getting into it often get fouled up–p and q can be anything between 0 and 1. They’re not 50%. Okay? They can be anything between 0 and 1. These genes can occur at arbitrary different frequencies; in the general case.
Well p plus q has got to equal 1, because we only have two possibilities; and that’s just the definition of frequencies. The frequencies of the kinds of zygotes they will form are p2, 2pq and q2, and those frequencies also add up to 1. The assumptions behind those statements are that meiosis is fair–so it’s just like flipping a coin, it’s 50% probability whether you’ll get one or the other allele in any particular mating–that mating is random, that there are large populations, and that there’s no selection and there’s no migration.
So this is kind of an ideal Gas Law for biology, and such laws are very useful in physics and chemistry, and this one is particularly useful in evolution. It tells us that if these assumptions hold, then in every generation you can expect those proportions of genotypes; no mutation.
Well what does it mean? It means that if you start in one generation with frequencies p and q, and you go through that kind of mating, you get zygotes with these frequencies, and in the next generation you get the same gamete frequencies; nothing changes. It’s kind of funny that you would place a lot of emphasis on a law that says that nothing changes. But in fact it’s extremely important, because it means that, at the level of a population, genetic information doesn’t disappear. Gene frequencies stay the same, and that means that the population gets replicated, the whole population gets replicated.
That allows information to accumulate. If this were not true, then the information that had been accumulated would get eroded by just the basic process of genetics. It turns out that genetics and random mating, and, uh, the whole structure of the Hardy-Weinberg assumptions, is set up in such a way that information is preserved at the level of the population. That makes evolution possible. If we didn’t have that retention of information, then you couldn’t tweak it; it would get eroded by processes other than natural selection.
So it’s kind of an inheritance mechanism at the whole population level. And, by the way, it minimizes conflicts among genes about who gets into the next generation. And genetic conflict will be something that we examine in more detail later on; particularly interesting in the context of evolutionary medicine and reproductive biology.
Okay, let’s go back to our problem. Jill and John have this baby, and the baby is at issue. So Jill’s got–Jill is a–I’m now going to use the words, to drive them home–Jill is a recessive homozygote. She’s got two copies of a. John could be either a dominant homozygote, or he could be a heterozygote; he’s got brown eyes. The baby’s got blue eyes, and is a recessive homozygote. Should John be worried?
Well here’s the hint. This is the one new piece of information I’m going to give you. We’re going to assume that John’s genotype is a random sample of those on the island, and therefore that q2–that’s the frequency of aa–is 0.01. So if q2 is 0.01, what is q? .1. Right; 10% probability. What’s the probability that John is a heterozygote? This requires having picked up information very rapidly. It’s 2pq. Okay? Those are the heterozygotes. The probability that John is a dominant homozygote is p2; p is .9; p2 is .81; 81% probability that John is a homozygote.
Should John be worried; I mean, just on genetic grounds? The only way that that baby could be John’s child is if he is a heterozygote. 2pq is 18%; p2 is 81%. Okay? So I did that just to give you a problem that has a little bit of human content to it, that is answered by genetics and by the concepts that we were playing with today.
Well if he, in fact, is a homozygote, there is no way that that child is his, unless he–no, there is a way. He could’ve had a mutation in the gene that turned it from a brown into a blue gene, and that could’ve found its way into the sperm that fathered the child; and the probability of that happening is about 10-9.