

Mosaic of amphorae being unloaded from a ship, Ostia / Southampton University, Creative Commons
The trade networks of the Roman Empire are among the most intensively researched large-scale market systems in antiquity,




By (left-to-right) Dr. Xavier Rubio-Campillo, María Coto-Sarmiento, Jordi Pérez-Gonzalez, and Dr. José Remesal Rodríguez
Rubio-Campillo: Lecturer in Archaeology; Computational Archaeology, The University of Edinburgh
Coto-Sarmiento: Department of Computer Applications in Science and Engineering, Barcelona Supercomputing Center
Pérez-Gonzalez: PhD Candidate, Department of History and Archaeology, University of Barcelona
Remesal Rodríguez: Department of Prehistory, Ancient History and Archaeology, University of Barcelona
Abstract
The trade networks of the Roman Empire are among the most intensively researched large-scale market systems in antiquity, yet there is no consensus on the economic structure behind this vast network. The difficulty arises from data fragmentation and the lack of formal analytical methods. Here, the authors present a Bayesian analysis quantifying the extent to which four previously proposed hypotheses match the evidence for the market system in Roman olive oil. Results suggest that the size of economic agents involved in this network followed a power-law distribution, strongly indicating the presence of free market structures supplying olive oil to Rome. This new analysis offers an important tool to researchers exploring the impact of trade on the dynamics of past societies.
Introduction
Trade is one of the most important social interactions in human societies. Intuition suggests that we should find evidence of common patterns in trade activities at different periods and in different territories. Trade activities also show, however, a large degree of diversity that needs to be considered. This diversity is particularly relevant when examining past economies distinct from our own(Oka&Kusimba 2008). Contrasting dynamics generate many research questions: how did trade networks change over time? What role did communication play? What factors promoted the collapse or emergence of trade routes?
These challenges are even more relevant for long-range trade requiring complex organisation. The Mediterranean is one of the most heavily studied areas to have developed intensive long-range trade. Benign climatic conditions encouraged maritime mobility, and, as a consequence, cultural exchange flourished between regions thousands of kilometres apart (Bevan 2014). This feedback loop between economic and political processes reached its peak during the Roman Empire (first to third centuries AD). Despite the abundance of archaeological data for this activity, some of the dynamics behind this interconnected economy are still subject to debate (e.g. Carreras & Soto 2013; Brughmans & Poblome 2016; Orengo & Livarda 2016).
The archaeological record provides a wealth of evidence, such as the vast quantities of amphorae used to ship liquid products. Assumptions regarding the use of these containers have, however, been recently challenged. Such assumptions include the lack of re-use, or the
unambiguous association between amphora types and their contents (Romanus et al. 2009; Foley et al. 2012; Pecci et al. 2017). In addition, proposed patterns of increase or decrease
in trade activities based on the frequency distribution of amphorae could also be explained
by the use of containers that rarely survive in the archaeological record, such as barrels and
skins (Wilson 2009).
All of these uncertainties affect the field of Roman economy studies (Bowman & Wilson
2009). Rome was one of the largest economies of the past, but was the Roman world really
interconnected? What role did the state play? Did political unification promote economic growth? The lack of clear archaeological proxies for the structure of Roman markets sparked
a long and heated debate between the initial modernist, almost-capitalistic perspective, and the opposed primitivists. A number of works have recently recognised the diversity of dynamics within Roman trade (e.g. Finley 1999; Scheidel et al. 2007; Scheidel 2012). These recent works highlight the need to apply quantitative methods to study the spectrum of market structures (Bowman & Wilson 2009; Scheidel 2014). This is not an easy task: working hypotheses often overlap and most of them probably explain only a small part of the entire picture. It is also not clear what type of archaeological proxy is required to evaluate the hypotheses, due to the data uncertainty already mentioned. Ultimately, it seems unrealistic to assume that a traditional statistical framework would be able, from existing evidence, to reject competing hypotheses.
It is important to note that these challenges are not restricted to Roman studies, nor to study of the past. There is a growing debate concerning the need to develop research frameworks able to quantify the plausibility of different hypotheses addressing existing data (Johnson & Omland 2004; Towner & Luttbeg 2007; Crema et al. 2014; Kandler & Powell 2015; Buck&Meson 2015; Rubio-Campillo 2016).
Bayesian inference is a statistical framework particularly well suited to confront this challenge by model selection. It is founded on the premise that knowledge of a given system with its associated uncertainty can gradually be updated through new evidence. First, competing hypotheses are transformed into a set of statistical models and parameters. The possible values for each parameter receive an initial probability (i.e. a prior), following a specific statistical distribution based on existing knowledge. A likelihood function is used to derive the probabilities of any given result by assessing the value of the input parameters. The updated knowledge (i.e. the posterior distribution) is then computed to infer a) the probability that a given model generated the existing evidence; and b) the relative explanatory power of a set of competing models.
The framework of model selection that we have developed is designed to quantify the extent to which different market structures match the evidence for long-range trade within the Roman Empire. The approach has been applied to a dataset of thousands of codes stamped in amphora handles collected from Monte Testaccio in Rome. This evidence was used to infer the market structure of the massive olive-oil trade system that supplied the capital from the production area of the Guadalquivir River, located in the Hispania Baetica province. Bayesian inference has then been applied to evaluate four previously suggested models by examining their explanatory power in relation to the dataset.
Archaeological Proxies of Market Structures

Figure 1. Dressel 20 amphora with a stamp, PNN, in one of its sides (after Aguilera Martín 2012).
Monte Testaccio is a 45m-high artificial mound in Rome located near to the east bank of the Tiber. It was created through the deposition of thousands of amphorae following their shipment to the city via river transport. Most of the excavated materials are identified as Dressel 20 amphorae, similar to those depicted in Figure 1. This amphora type is typically associated with Baetican olive oil, which was widely distributed from southern Spain throughout the western Empire from the first to the third centuries AD (Remesal Rodríguez 1998).
A large percentage of Dressel 20 amphorae displayed a stamp identifying an economic agent linked to the container (see Figure 2 for an example of the most frequently found code from Monte Testaccio). It has been suggested that the stamped code identifies the owner of the land where the olives were harvested and the oil was produced (Garlan 1983; Remesal Rodríguez 2013). Other authors suggest that the stamp refers to the workshop that made the amphorae (Funari 1996; Berni Millet 2008). Whichever is the case, the actors identified in the stamps were part of a common economic activity linked to long-range trade.

Figure 2. Photograph and digitised version of a stamp where PNN can be read. It is the most common code found in the dataset, and its three letters probably identify the initials of a full Roman name or tria nomina.
The number of stamps displaying the same code was chosen as the archaeological proxy of the actor’s weight within the market. This proxy is relative, as it does not define the absolute production of each actor. A code displayed in 100 stamps will, however, naturally identify an individual with higher economic weight than another represented by a code found in 5 stamps. The aggregated frequency distribution of the codes is used as the proxy for the entire market structure (i.e. the number of agents displaying the same frequency value).
Our analysis used a dataset of 7520 stamps collected from 10 different excavations at Monte Testaccio, from 1990–2014 (Blázquez et al. 1994; Blázquez & Remesal Rodríguez 1999, 2001, 2003, 2007, 2010, 2014). The chronological span of these remains covers 117 years (from AD 143–260). A quarter of these stamps were incomplete due to fragmentation or erosion, and a probabilistic model was created to integrate this uncertainty into the analysis by assigning complete codes to incomplete stamps. The method then used Monte Carlo simulation to generate a dataset ready to be analysed (the complete process is described in the online supplementary material (OSM), section 1).
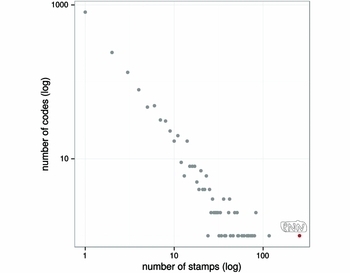
Figure 3. Empirical frequency distribution of codes in stamps. The plot shows the number of codes (y-axis) appearing in a given number of stamps (x-axis). The red dot depicts the code PNN, which has the largest number of repetitions (253). Both axes are transformed to logarithmic scale.
Figure 3 shows the frequency distribution of the codes found in the amphora dataset. It can be observed that the shape is dominated by a heavy tail, but further analysis is required to assess the validity of each competing hypothesis.
Model Selection Framework
Four market structures were evaluated against this archaeological proxy. The competing models were chosen from previously published studies that could be linked to olive-oil trade within the Roman Empire.
- H1: balanced model: Demand is fulfilled by the aggregation of small-scale production units (Poblome et al. 2013). This would translate into several agents of similar capacity.
- H2: balanced model with large actors: Political connections alter the previous dynamic by creating large-scale producers linked to the state (e.g. Erdkamp 2005: 109, for grain trade).
- H3: concentration dynamics: Farming activities are often characterised by a minimum threshold, below which production is not sustainable. As a consequence, small agents are absorbed by larger agents and land ownership is gradually concentrated (Allanson 1992).
- H4: Pareto principle: A self-organised and interconnected economic system follows the Pareto principle: 80 percent of the market is controlled by 20 per cent of its agents (Axtell
2001). This structure would generate a small number of large-scale producers complemented by a large number of small-scale producers.

The focus on the code frequency distributions allowed us to translate the hypotheses above into statistical models (as summarised in Table 1). This approach captured the
properties of each suggested structure while accepting a certain degree of stochasticity:
- M1 transformed H1 into a Poisson distribution where parameter λ defines the average size for the entire set of producers.
- M2 used a negative binomial distribution to generate a heavy tail composed of a few large-scale producers, according to H2.
- M3 represented the concentration process of H3 as a log-normal distribution. The shape of this model is able to represent: a) a lack of small producers; b) the predominance of mid-sized producers; and c) a heavy tail of large-scale producers.
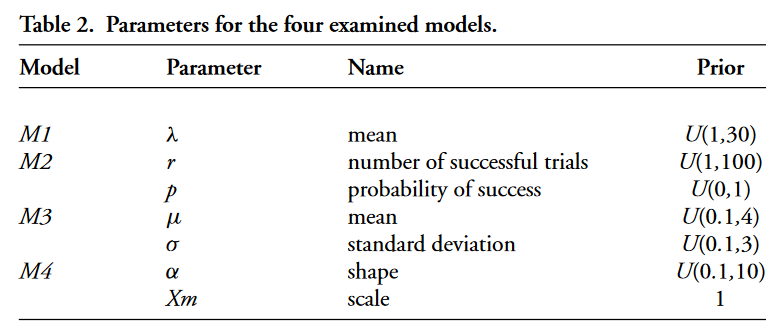
The analytical framework chosen for model selection was based on Bayesian inference. The translation of the hypotheses into statistical models allowed us to compute the posterior distributions easily using Markov chain Monte Carlo (MCMC). Uninformed prior beliefs were chosen for all the models, as summarised in Table 2. The OSM, section 2, lists the parameters used in the MCMC execution. The entire framework was implemented using R, Jags and R2Jags (Plummer 2003; Su&Yajima 2015; RCoreTeam 2016).
The final step of the method was to quantify the plausibility of the four competing models, taking into account a) the goodness of fit to the evidence; and b) their degree of parsimony. The Deviance Information Criterion (DIC) was chosen for this task, as it is an intuitive information-based measure equivalent to popular indices, such as the Akaike Information Criterion (Spiegelhalter et al. 2002, 2014). Despite some limitations, DIC is a method commonly used in Bayesian inference when the posterior distributions are approximately multivariate-normal. This measure allows the researcher to take into account both the complexity and the deviance from the model’s outcome to existing evidence, thereby quantifying parsimony and goodness of fit within a Bayesian framework.
Results
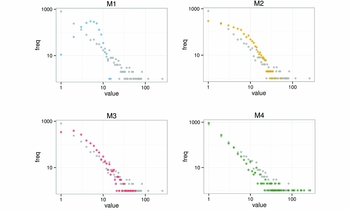
Figure 4. Comparison between evidence and models. Grey dots display the frequency distributions of codes in stamps, while coloured points show random deviates generated with the mean values obtained from the posterior distributions.
All posterior distributions follow unimodal shapes, thus suggesting that the signal in the dataset is strong enough to overcome noise and generate consistent results (as can be seen in the OSM, section 3). The goodness of fit of the models can first be explored by comparing the evidence against simulated data obtained from each model. Figure 4 shows the results generated by each model using the mean of each posterior distribution as parameter values. The two balanced models (M1 and M2) generate patterns substantially different from the observations. Models M3 and M4 are closer to the frequency distribution of the collected stamps. The fitness of M3 and M4 suggests the presence of some producers of significantly larger size than the average value of the sample. This could have resulted from a concentration process generated by the market. The huge demand for olive oil generated by the city of Rome must surely have put a lot of pressure on the production of this commodity. Consequently, Baetican producers could have generated economies of scale in order to maximise the efficiency of the existing infrastructures.
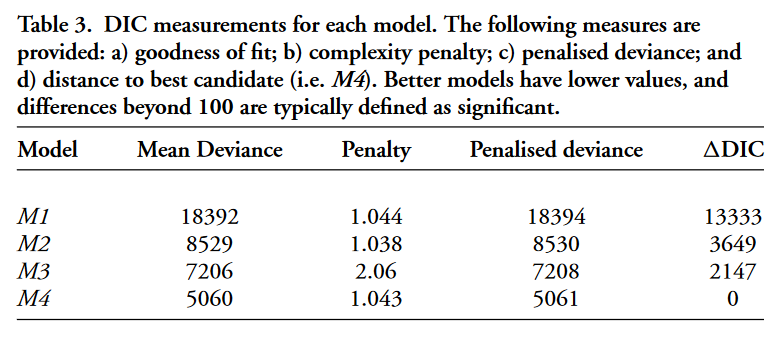
DIC values for the four models are summarised in Table 3. Comparison of these measures suggests that the best fit for this sample is a power-law distribution, in which most olive-oil producers identified by stamps were very small, while concentration processes created a significant quantity of middle-sized agents and a very small number of large-scale producers.
Even though it is not usually possible to identify these large actors, they were probably linked to the Roman political system (i.e. members of the Senate or the imperial family).
Discussion
The identification of a power-law distribution requires consideration of the mechanism causing this distinct signal in the evidence (Stumpf & Porter 2012). This statistical distribution has received considerable attention since its creation, owing to its unique properties. One of the most distinctive characteristics is that power-laws exhibit scale invariance (i.e. the features of the distribution remain constant over the entire range). If both axes of the power-law are transformed to a logarithmic scale, the sample will follow a straight line (this can be observed in
Figure 4).
Power-laws have been identified in disciplines as varied as physics, ecology, sociology and linguistics (Clauset et al. 2009 ). Their transdisciplinary relevance is explained by the fact that power-laws are proxies for self-organised optimal systems with some degree of hierarchy (Newman 2005). It would be very difficult to generate a power-law by external causes on account of scale invariance, but a power-law emerges when evolutionary dynamics enforce optimality by selection.
Free markets are complex systems fulfilling both self-organisation and optimality, and could therefore be the underlying process generating the shape of our dataset. This prediction has been proved elsewhere in contemporary case studies (Axtell 2001). Although we cannot disregard the possibility that the pattern detected here was generated by a different structure, the simplest interpretation for our results is that the Roman olive-oil trade was organised as a free market. This is the outcome that would be expected by researchers who have documented the existence of private enterprise (e.g. Temin 2001, 2013). It is difficult to conceive how a state-organised market could generate a power-law. It would require a structure with thousands of small-sized producers complemented by a few large-sized agents. The creation of this organisation, if at all possible, would have required the investment of a large amount of resources and fine control over the system. Finally, the nature of the dataset also supports the existence of a densely interconnected free market, as the amphora stamps that follow the power-law were made 2000km from Rome.
The work presented here has its limitations, as does any other model. Our analysis, for example, cannot confirm whether the stamps identify olive-oil producers or pottery makers. The first option seems more plausible, as it could generate the economies of scale needed to produce a power-law; it is feasible that an olive-oil producer owned an area much larger than the competitors, while a pottery workshop could not be hundreds of times bigger than its competitors due to physical constraints. Neither hypothesis can, however, be discarded, unless new data are discovered. This uncertainty does not invalidate our results, as the analysis indicates long-range trade activity exhibiting free market properties independently of the agents identified by the stamps (olive-oil producers or amphora producers).
Power-law distributions are ubiquitous to datasets deriving from contemporary activities, but they are less commonly observed in archaeological datasets (Bentley & Maschner 2003; Bentley & Shennan 2003; Grove 2011; Haas et al. 2015). Several studies show how their dataset’s shape follows a power-law only in the heavy tail, while the left segment does not match the log-log straight line. These partial fits could, however, also be explained by log-normal distributions, as in our model M3 (for discussion within archaeology, see Bentley 2003; beyond archaeology, see Allen et al. 2001; Eeckhout 2004; Levy 2009). This distinction is important, as the two shapes are generated by critically different social phenomena. Log-normal distributions are essentially produced by additive processes, while power-laws emerge from complex self-organised systems and indicate a higher degree of inequality and interaction amongst their components. Additionally, log-normal distributions display an arithmetic mean value (i.e. there is an average size of producers), while power-laws do not.
The analysis presented here has revealed one of the first examples of an archaeological dataset that follows a complete power-law distribution. There are probably very few contexts that meet the conditions required for the development of a large-scale integrated market. The subset of these scenarios, where the structure of the market can be found in the archaeological record, is even lower, due to a diversity of taphonomic processes (i.e. survivorship bias). We have identified a power-law distribution within an economy quite different from contemporary systems, thus suggesting that the same pattern could be identified in other case studies. Additional research is needed to understand whether this power-law is an isolated scenario specific to the Roman Empire, or a general pattern within the trade networks of past societies.
References
Aguilera Martín, A. 2012. La normalisation de l’épigraphie amphorique: les tituli picti des amphores Dressel 20, in M.E. Fuchs, R. Sylvestre & C.S. Heidenreich (ed.) Inscriptions mineures: nouveautés et réflexions. Actes du premier colloque Ductus: 135–43. Lausanne: Université de Lausanne.
Allanson, P. 1992. Farm size structure in England and Wales 1939–89. Journal of Agricultural Economics 43: 137–48.
Allen, A., B.-L. Li & E. Charnov. 2001. Population fluctuations, power laws and mixtures of lognormal distributions. Ecology Letters 4(1): 1–3.
Axtell, R.L. 2001. Zipf distribution of U.S. firm sizes. Science 293: 1818–20.
Bentley, R.A. 2003. Scale-free network growth and social inequality, in R.A. Bentley & H.D. Maschner (ed.) Complex systems and archaeology: 27–46. Salt Lake City: University of Utah Press.
Bentley, R.A. & H.D. Maschner (ed.). 2003. Complex systems and archaeology. Salt Lake City: University of Utah Press.
Bentley, R.A. & S.J. Shennan. 2003. Cultural transmission and stochastic network growth.
American Antiquity 68: 459–85.
Berni Millet, P. 2008. Epigrafía anfórica de la Bética. Nuevas formas de análisis (Col· lecció Instrumenta 29). Barcelona: Universitat de Barcelona.
Bevan, A. 2014. Mediterranean containerization. Current Anthropology 55: 387–418.
Blázquez, J.M. & J. Remesal Rodríguez (ed.). 1999. Estudios sobre el Monte Testaccio (Roma) 1 (Col· lecció Instrumenta 6). Barcelona: Universitat de Barcelona.
−2001. Estudios sobre el Monte Testaccio (Roma) 2 (Col· lecció Instrumenta 10). Barcelona: Universitat de Barcelona.
−2003. Estudios sobre el Monte Testaccio (Roma) 3 (Col· lecció Instrumenta 14). Barcelona: Universitat de Barcelona.
−2007. Estudios sobre el Monte Testaccio (Roma) 4 (Col· lecció Instrumenta 24). Barcelona: Universitat de Barcelona.
−2010. Estudios sobre el Monte Testaccio (Roma) 5 (Col· lecció Instrumenta 35). Barcelona: Universitat de Barcelona.
−2014. Estudios sobre el Monte Testaccio (Roma) 6 (Col· lecció Instrumenta 47). Barcelona: Universitat de Barcelona.
Blázquez, J.M., J. Remesal Rodríguez & E. Rodríguez Almeida (ed.). 1994. Excavaciones
arqueológicas en el Monte Testaccio (Roma). Memoria campaña 1989. Madrid: Ministerio de Cultura.
Bowman, A.&A. Wilson. 2009. Quantifying the Roman economy. Oxford: Oxford University Press.
Brughmans, T.&J. Poblome. 2016. Roman bazaar or market economy? Explaining tableware
distributions through computational modelling. Antiquity 90: 393–408.
Buck, C.E. & B. Meson. 2015. On being a good Bayesian. World Archaeology 47: 567–84.
Carreras, C.& P. D . Soto. 2013. The Roman transport network: a precedent for the integration
of European mobility. Historical Methods: a Journal of Quantitative and Interdisciplinary History
46(3):117–33.
Clauset, A., C.R. Shalizi & M.E.J. Newman. 2009. Power-law distributions in empirical data.
SIAM Review 51: 661–703.
Crema, E., K. Edinborough, T. Kerig & S. Shennan. 2014. An approximate Bayesian computation approach for inferring patterns of cultural evolutionary change. Journal of
Archaeological Science 50: 160–70.
Eeckhout, J. 2004. Gibrat’s law for (all) cities. American Economic Review 94: 1429–51.
Erdkamp, P. 2005. The grain market in the Roman Empire: a social, political and economic study. Cambridge: Cambridge University Press.
Finley, M.I. 1999. The ancient economy. Berkeley: University of California Press.
Foley, B.P., M.C. Hansson, D.P. Kourkoumelis & T.A. Theodoulou. 2012. Aspects of ancient Greek trade re-evaluated with amphora DNA evidence. Journal of Archaeological Science 39: 389–98.
Funari, P. P. A . 1996. Dressel 20 inscriptions from Britain and the consumption of Spanish olive oil (British Archaeological Reports international series 250). Oxford: British Archaeological Reports.
Garlan, Y. 1983. Greek amphorae and trade, in P. Garnsey, K. Hopkins & C.R. Whittaker (ed.)
Trade in the ancient economy: 27–35. Berkeley: University of California Press.
Grove, M. 2011. An archaeological signature of multi-level social systems: the case of the Irish
Bronze Age. Journal of Anthropological Archaeology 30(1): 44–61.
Haas, W. R ., C.J. Klink, G.J. Maggard & M.S. Aldenderfer. 2015. Settlement-size scaling among prehistoric hunter-gatherer settlement systems in the new world. PLoS ONE 10: e0140127.
Johnson, J.B. & K.S. Omland. 2004. Model selection in ecology and evolution. Trends in Ecology & Evolution 19(2): 101–108.
Kandler, A.&A. Powell. 2015. Inferring learning strategies from cultural frequency data, in A. Mesoudi & K. Aoki (ed.) Learning strategies and cultural evolution during the Palaeolithic: 85–101. Tokyo: Springer Japan.
Levy, M. 2009. Gibrat’s law for (all) cities: comment. American Economic Review 99: 1672–75.
Newman, M. 2005. Power laws, pareto distributions and Zipf’s law. Contemporary Physics
46: 323–51.
Oka, R. & C.M. Kusimba. 2008. The archaeology of trading systems, part 1: towards a new trade synthesis. Journal of Archaeological Research 16:339–95.
Orengo, H.A. & A. Livarda. 2016. The seeds of commerce: a network analysis-based approach to the Romano-British transport system. Journal of Archaeological Science 66: 21–35.
Pecci, A., J. Clarke, M. Thomas, J. Muslin, I. van der Graaff, L. Toniolo, D. Miriello, G.M. Crisci, M. Buonincontri & G. Di Pasquale. 2017. Use and reuse of amphorae. Wine residues in Dressel 2–4 amphorae from Oplontis Villa B (Torre Annunziata, Italy). Journal of Archaeological Science: Reports 12: 515–21.
Plummer, M. 2003. Jags: a program for analysis of Bayesian graphical models using Gibbs sampling, in K. Hornik, F. Leisch & A. Zeileis (ed.) Proceedings of the 3rd International Workshop on Distributed Statistical Computing: 1–10. Vienna: Technische Universität Wien.
Poblome, J.,P. Bes & R. Willet. 2013. Thoughts on the archaeological residue of networks. A view from the East, in S. Keay (ed.) Rome, Portus and the Mediterranean (Archaeological Monographs of the British School at Rome 21): 393–401. Rome: British School at Rome.
R Core Team. 2016. R: a language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.
Remesal Rodríguez, J. 1998. Baetican olive oil and the Roman economy. Journal of Roman Archaeology supplementary series 29: 183–200.
−2013. El Monte Testaccio. De vertedero a archivo. Atti della Pontificia Accademia romana di
Archeologia (Serie III). Rendiconti LXXXV:111–28.
Romanus, K., J. Baeten, J. Poblome, S. Accardo, P. Degryse, P. Jacobs, D. De Vos & M. Waelkens. 2009. Wine and olive oil permeation in pitched and non-pitched ceramics: relation with results from archaeological amphorae from Sagalassos, Turkey. Journal of Archaeological
Science 36: 900–909.
Rubio-Campillo, X. 2016. Model selection in historical research using approximate Bayesian
computation. PLoS ONE 11: e0146491.
Scheidel, W. (ed.). 2012. The Cambridge companion to the Roman economy. Cambridge: Cambridge University Press.
−2014. The shape of the Roman world: modelling imperial connectivity. Journal of Roman Archaeology 27: 7–32.
Scheidel, W., I. Morris & R.P. Saller (ed.). 2007. The Cambridge economic history of the Greco-Roman world. Cambridge & New York: Cambridge University Press.
Spiegelhalter, D.J., N.G. Best, B.P. Carlin & A. van der Linde. 2002. Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 64: 583–639.
−2014. The deviance information criterion: 12 years on. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 76: 485–93.
Stumpf, M.P.H. & M.A. Porter. 2012. Critical truths about power laws. Science 335: 665–66.
Su, Y.-S. & M. Yajima. 2015. R2jags: using R to run ‘JAGS’. R package version 0.5–7. Available at: https://rdrr.io/cran/R2jags/ (accessed 9 June 2017).
Temin, P. 2001. A market economy in the early Roman Empire. Journal of Roman Studies 91: 169–81.
−2013. The Roman market economy. Princeton (NJ): Princeton University Press.
Towner, M.C. & B. Luttbeg. 2007. Alternative statistical approaches to the use of data as evidence for hypotheses in human behavioral ecology. Evolutionary Anthropology: Issues, News, and Reviews 16(3): 107–18.
Wilson, A. 2009. Approaches to quantifying Roman trade, in A. Bowman & A. Wilson (ed.)
Quantifying the Roman economy: 213–49. Oxford: Oxford University Press.
Originally published by Antiquity 91:359 (2017, 1241-1252) under the terms of a Creative Commons Attribution 4.0 International license.


